今天的內容來到資料處理啦!介紹的是用Pandas來練習,這裡參考的是Quick Introduction to pandas,裡面詳細介紹了在Colab中可以進行的各種實作。
Pandas是一個在python中廣泛使用的數據分析式函式庫,提供強大數據結構和工具,處理和分析結構化數據。其中主要引入的兩種數據結構:
<引用Pandas>
import pandas as pd
pd.__version__
再來認識一下Series的運作:
pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
這裡的意思是Series內有一個陣列,放三個城市,就是一個完整的Series了。
現在要來把Series放進DataFrame:
city_names = pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
population = pd.Series([852469, 1015785, 485199])
pd.DataFrame({ 'City name': city_names, 'Population': population })
就會形成表單: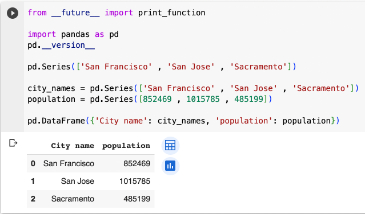
知道原理後可以來輸入外部資料,因為數據很多幾千幾萬筆,手動輸入有點笨,提供範例:
california_housing_dataframe = pd.read_csv("https://download.mlcc.google.com/mledu-datasets/california_housing_train.csv", sep=",")
california_housing_dataframe.describe()
執行後會看到: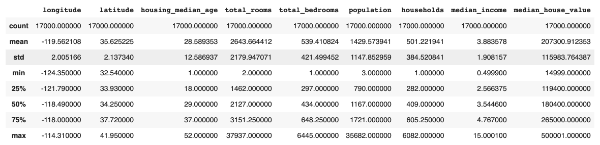
今天大概介紹了Pandas資料庫,會發現真的很方便且實用,他也很適合清裡、轉換等工作,明天會繼續說明!

